1. 准确率 (Accuracy)
定义:准确率是指模型预测正确的样本占总样本的比例。
公式:
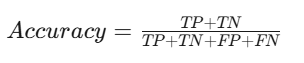
- TP (True Positive):真正例,正确预测为正类的样本数量。
- TN (True Negative):真负例,正确预测为负类的样本数量。
- FP (False Positive):假正例,错误预测为正类的样本数量。
- FN (False Negative):假负例,错误预测为负类的样本数量。
解释:准确率是一个常用的性能指标,但在类别不平衡的情况下可能会产生误导。例如,如果大多数样本是负类,模型只需简单地预测所有样本为负类即可获得高准确率。
2. 精确率 (Precision)
定义:精确率是指模型预测为正类的样本中,实际为正类的比例。
公式:
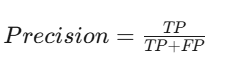
解释:精确率衡量的是模型在预测为正类时的准确性。在某些应用中(如疾病筛查),我们希望尽量减少假阳性,因为假阳性可能导致不必要的后续检查或治疗。
3. 召回率 (Recall)
定义:召回率是指实际为正类的样本中,被模型正确预测为正类的比例。
公式:
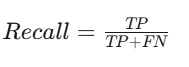
解释:召回率衡量的是模型对正类样本的识别能力。在某些情况下(如癌症检测),我们希望尽量减少假阴性,因为漏掉一个真实的阳性样本可能会导致严重后果。
4. F1 值
定义:F1 值(F1-score)是分类问题中的一种综合评价指标,它是精确率和召回率的加权平均,用于同时考虑预测出的正例和实际正例的数量,其中 F1 也称为精确率和召回率的调和均值。
公式:
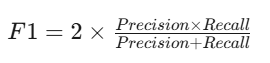
解释:单独用精确率或者召回率不能很好的评估模型好坏。当 P 和 R 同时为 1 时,F1=1。当有一个很大,另一个很小的时候,比如 P=1,R~0,此时 F1~0。分子 2PR 的 2 完全了为了使最终取值在 0-1 之间,进行区间放大,无实际意义。
5. 特异度(Specificity)
- 定义:模型预测为负类且正确的样本数占实际为负类的样本总数的比例。
- 公式:
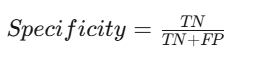
- 适用场景:关注负类预测准确性时。
6. ROC 曲线下面积(AUC-ROC)
- 定义:接收者操作特征曲线(ROC Curve)下的面积。
- 解释:衡量模型在不同阈值下对正负类的区分能力。
- 适用场景:数据分布均衡或不均衡时。
8. 马修斯相关系数(MCC)
- 定义:衡量二分类模型质量的指标,考虑了所有混淆矩阵元素。
- 公式:
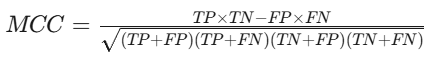
- 适用场景:数据分布不均衡时。
9. PR 曲线下面积-AUPRC(Area Under the Precision-Recall Curve)
正类很少时,ROC 容易“乐观”,AUPRC 更严格:它把“召回率”当横轴,“精确率”当纵轴,曲线下的面积越大,模型找少数类越准。
from sklearn.metrics import average_precision_score
auprc = average_precision_score(y_true, y_score) # 直接给出 AUPRC